

La révolution de l’IA générative, incarnée par des outils comme ChatGPT, Midjourney et bien d’autres, repose sur l’entraînement de vastes réseaux de neurones sur d’immenses jeux de données web. Ces grands modèles de langage (LLM) peuvent répondre à divers types de requêtes : questions, rédaction de code ou de poèmes. Les systèmes de génération d’images peuvent quant à eux créer des œuvres convaincantes dans différents styles artistiques.
Pourtant, malgré leurs capacités étonnantes, ces IA ne se sont pas encore matérialisées sous forme de robots polyvalents comme dans la science-fiction, capables d’accomplir des tâches ménagères variées.
La raison est que la formule de l’IA générative, basée sur des données web, ne s’applique pas facilement à la robotique. En effet, Internet ne regorge pas de données d’interaction robot-environnement comme de textes et d’images. Les robots doivent apprendre à partir de données créées spécifiquement en laboratoire, un processus lent et fastidieux limité à des tâches particulières.
Malgré les avancées algorithmiques, le manque de données abondantes empêche les robots d’accomplir des tâches complexes hors des laboratoires pour l’instant. Les résultats impressionnants restent généralement limités à un seul robot, un seul lab et quelques comportements.
Mais que se passerait-il si l’on pouvait regrouper les expériences de nombreux robots pour qu’un nouveau puisse apprendre de tous à la fois ? C’est l’objectif du projet RT-X lancé en 2023, qui rassemble 33 laboratoires pour partager données, ressources et code en vue de créer des robots véritablement polyvalents.
Voici ce que nous avons appris de la première phase de cet effort.
Comment créer un robot polyvalent
Les humains ont une excellente capacité d’adaptation et d’apprentissage. Notre cerveau peut, avec un peu d’entraînement, s’ajuster à des modifications de notre « schéma corporel ». C’est ce qui se produit quand nous utilisons un outil, faisons du vélo ou conduisons une voiture : notre façon d’interagir avec l’environnement change, mais notre cerveau s’y adapte.
Le projet RT-X vise à reproduire cette capacité d’adaptation chez les robots, en permettant à un seul réseau neuronal profond de contrôler différents types de robots. On appelle cela la « cross-incarnation ». La question est de savoir si un tel réseau, entraîné sur des données issues d’une grande variété de robots aux formes, propriétés physiques et capacités très diverses, peut apprendre à les commander tous, aussi différents soient-ils. Si c’est possible, cela pourrait ouvrir la voie à l’exploitation de grands ensembles de données pour l’apprentissage robotique.
L’ampleur du projet est considérable, ce qui est nécessaire. L’ensemble de données RT-X contient près d’un million d’essais réalisés par 22 types de robots différents, dont plusieurs des bras robotisés les plus courants. Ces robots effectuent un large éventail de tâches : saisie et déplacement d’objets, assemblages, routage de câbles, etc. Au total, on dénombre environ 500 compétences distinctes impliquant des milliers d’objets. C’est l’ensemble de données libre le plus vaste jamais créé pour des actions robotiques réelles.
Fait surprenant, des méthodes d’apprentissage automatique relativement simples fonctionnent sur ces données multi-robots, à condition d’utiliser de grands réseaux neuronaux comme pour les LLM tels que ChatGPT. Sans fonctionnalité spécifique à la « cross-incarnation », ces modèles identifient simplement le type de robot à partir des images caméra, et envoient les commandes adéquates. Tout comme notre cerveau peut conduire une voiture ou faire du vélo, un modèle RT-X reconnaît s’il contrôle par exemple un bras UR10 industriel ou un petit bras WidowX de loisir, et l’actionne en conséquence.
Des résultats prometteurs, mais des défis à relever
Les résultats obtenus jusqu’à présent sont prometteurs. L’approche basée sur des données massives et un apprentissage automatique simple a permis de réaliser des progrès significatifs vers la création de robots polyvalents. Cependant, il reste encore beaucoup de chemin à parcourir. L’un des défis majeurs est la robustesse. Les robots doivent pouvoir fonctionner dans des environnements variés et face à des perturbations inattendues. Cela nécessitera des recherches supplémentaires sur l’apprentissage par renforcement et d’autres techniques d’apprentissage automatique.
Un autre défi est la généralisation. Actuellement, le jeu de données RT-X se concentre sur les bras robotisés. Pour que les robots deviennent vraiment polyvalents, ils devront être capables d’apprendre à effectuer une large gamme de tâches, y compris la locomotion, la manipulation d’objets délicats et l’interaction avec les humains. Cela nécessitera l’extension du jeu de données RT-X pour inclure plus de types de robots et de tâches.
Vers un avenir où les robots sont à notre service
Malgré ces défis, les résultats du projet RT-X sont encourageants. Ils montrent que la création de robots polyvalents est à portée de main. Avec des recherches et un développement supplémentaires, nous pouvons créer des robots qui peuvent nous aider dans nos tâches quotidiennes, améliorer notre qualité de vie et nous ouvrir de nouvelles possibilités.
L’avenir de la robotique est prometteur. Grâce à l’IA générative et à l’apprentissage automatique, nous sommes sur le point de créer des robots plus performants, plus polyvalents et plus utiles que jamais auparavant. Ces robots ont le potentiel de révolutionner de nombreuses industries et d’améliorer notre vie de bien des façons.
Pour tester les capacités de notre modèle, cinq des laboratoires participant à la collaboration RT-X l’ont comparé directement au meilleur système de contrôle qu’ils avaient développé indépendamment pour leur propre robot. Chaque test de laboratoire portait sur les tâches qu’il utilisait pour sa propre recherche, notamment la saisie et le déplacement d’objets, l’ouverture de portes et le passage de câbles dans des clips. Étonnamment, le modèle unifié unique a surpassé la meilleure méthode de chaque laboratoire, réussissant les tâches environ 50 % plus souvent en moyenne.
Ce résultat peut sembler surprenant, mais nous avons constaté que le contrôleur RT-X pouvait exploiter les expériences diverses d’autres robots pour améliorer la robustesse dans différents environnements. Même au sein d’un même laboratoire, chaque fois qu’un robot tente une tâche, il se retrouve dans une situation légèrement différente. Ainsi, s’appuyer sur les expériences d’autres robots dans d’autres situations a aidé le contrôleur RT-X à gérer la variabilité naturelle et les cas extrêmes. Voici quelques exemples de la variété de ces tâches :


Construire des robots capables de raisonner
Forts de leur réussite à entraîner un modèle unique sur les données de nombreux robots différents, les chercheurs ont ensuite voulu intégrer ces capacités physiques à des capacités de raisonnement sémantique plus poussées.
En effet, bien que les données robotiques puissent fournir un large éventail d’aptitudes physiques, des tâches complexes comme « Déplacer la pomme entre la boîte et l’orange » nécessitent aussi de comprendre les relations sémantiques entre objets, le sens commun élémentaire et d’autres connaissances symboliques non directement liées aux compétences motrices du robot.
Pour cela, une autre source massive de données a été ajoutée : les données d’images et de texte à l’échelle d’Internet. Un grand modèle existant de vision et langage, similaire à ChatGPT ou Bard et déjà compétent pour relier langage naturel et images, a été utilisé.
Ces modèles entraînés à produire du texte en réponse à des invites image/texte peuvent résoudre des problèmes comme répondre à des questions visuelles, générer des légendes, etc. Ici, ils ont été adaptés au contrôle robotique en les entraînant aussi à produire des actions robotiques en réponse à des commandes du type « Mettre la banane sur l’assiette ». Cette approche combinant connaissance sémantique et données robotiques RT-X a permis d’obtenir des systèmes robotiques à la fois polyvalents physiquement et capables de raisonner.
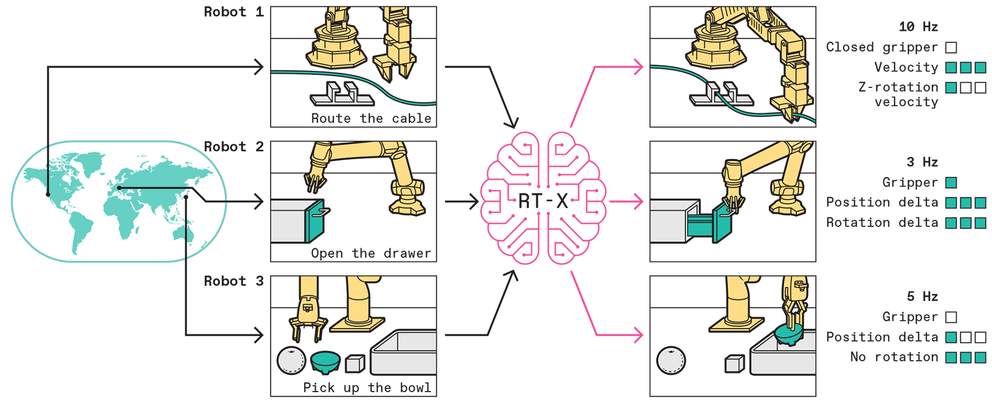
Le modèle RT-X utilise des images ou des descriptions textuelles de bras robotiques spécifiques effectuant différentes tâches pour générer une série d’actions discrètes permettant à n’importe quel bras robotique de réaliser ces mêmes tâches. En collectant des données provenant de nombreux robots effectuant de nombreuses tâches dans des laboratoires de robotique à travers le monde, nous construisons un ensemble de données open-source qui peut être utilisé pour enseigner aux robots à être généralement utiles.
Évaluer les robots polyvalents : Raisonnement et sens commun
Pour évaluer la combinaison des connaissances issues d’internet et des données multi-robots, le modèle RT-X a été testé sur le robot manipulateur mobile de Google dans les conditions de généralisation les plus difficiles.
Le robot devait à la fois reconnaître et manipuler des objets avec succès, mais aussi répondre à des commandes textuelles complexes nécessitant des inférences logiques à partir du texte et des images. C’est ce type de raisonnement intégré qui fait l’excellente polyvalence des humains.
Pouvait-on donner un aperçu de telles capacités aux robots? Deux séries d’évaluations ont été menées. Dans la première, un modèle n’incluant que les données spécifiques au robot Google (la plus grande partie avec plus de 100 000 démonstrations) a servi de référence, l’apport des autres données multi-robots restant à démontrer.
Dans la seconde évaluation, toutes les données multi-robots ont été incluses. Le robot Google devait alors accomplir des tâches très complexes comme « Déplacer la pomme entre la boîte et l’orange » ou « Placer un objet sur une feuille avec la solution de ‘2+3′ ». Ces défis testaient ses capacités cruciales de raisonnement et de déduction.
Pour y répondre, le modèle puisait ses connaissances sémantiques (sens de « entre », « sur », etc.) dans les données web, tandis que son aptitude à traduire ces raisonnements en actions robotiques concrètes (commander le bras) provenait de l’entraînement sur les données robotiques variées de RT-X.
La vidéo montre un exemple où le robot a dû effectuer une tâche totalement nouvelle pour lui, démontrant ses facultés de généralisation.
Même sans entraînement spécifique, ce robot de recherche de Google est capable de suivre l’instruction « déplacer la pomme entre la boîte de conserve et l’orange ». Cette capacité est rendue possible par RT-X, un vaste ensemble de données de manipulation robotique et le premier pas vers un cerveau robotique polyvalent.
Bien que rudimentaires pour les humains, ces tâches comme « Déplacer la pomme entre la boîte et l’orange » ou résoudre des additions simples représentent un défi majeur pour des robots polyvalents. Sans données de démonstration illustrant clairement les concepts de « entre », « près », « sur », etc., même un système entraîné sur de multiples robots ne pourrait pas comprendre le sens de telles commandes.
C’est en intégrant les vastes connaissances sémantiques d’un modèle de vision/langage entraîné sur le web que notre système complet a pu résoudre ces tâches. Il puisait les concepts sémantiques comme les relations spatiales dans cet entraînement internet, et les comportements moteurs comme saisir/déplacer des objets dans les données robotiques variées de RT-X.
Surprise : l’inclusion des données multi-robots a permis au robot Google de multiplier par 3 sa capacité à généraliser de telles tâches. Cela suggère que ces données RT-X ne servaient pas qu’à acquérir des compétences physiques, mais aussi à mieux relier ces dernières aux connaissances sémantiques/symboliques des modèles vision/langage.
Ces connexions dotent en quelque sorte le robot d’un « bon sens » qui pourrait un jour lui permettre de comprendre des commandes complexes comme « Apporte-moi mon petit-déjeuner » tout en réalisant les actions nécessaires.
Les prochaines étapes de RT-X
Le projet RT-X montre ce qui est possible quand la communauté de l’apprentissage robotique agit de concert. Grâce à cet effort interinstitutionnel, un vaste ensemble de données robotiques diversifiées a pu être constitué, permettant des évaluations multi-robots complètes qu’un seul laboratoire ne pourrait réaliser.
Contrairement à d’autres domaines qui peuvent s’appuyer sur le web, la robotique doit créer elle-même ses données d’entraînement. L’équipe espère donc que davantage de chercheurs contribueront à enrichir la base RT-X et se joindront à cette collaboration.
L’objectif est également de fournir des outils, modèles et une infrastructure pour soutenir la recherche sur le « cross-embodiment » (contrôle de robots variés par un même système). Au-delà du simple partage de données, RT-X vise à devenir un effort collaboratif pour développer des standards, des modèles réutilisables, de nouvelles techniques et algorithmes.
Les premiers résultats donnent un aperçu de la façon dont les grands modèles robotiques « cross-embodiment » pourraient transformer le domaine. Tout comme les grands modèles de langage excellent dans de nombreuses tâches textuelles, on pourrait à l’avenir utiliser le même modèle de base pour diverses tâches robotiques réelles.
De nouvelles compétences pourraient peut-être être acquises par un simple ajustement ou en adressant une commande au modèle pré-entraîné, comme on demande à ChatGPT de rédiger un texte sans l’avoir spécifiquement entraîné dessus. Par exemple, demander à un robot d' »Écrire Joyeux Anniversaire sur un gâteau » sans lui avoir appris la poche à douille ou la calligraphie.
Bien sûr, beaucoup de recherches seront encore nécessaires pour atteindre cette généralisation, les expériences actuelles se limitant à des manipulations simples par des bras à pinces. Mais la voie est tracée.
À mesure que davantage de laboratoires se consacreront à la recherche sur le « cross-embodiment », on espère repousser encore les limites de ce qu’un seul réseau neuronal sera capable de réaliser en contrôlant de nombreux robots différents.
Ces progrès pourraient inclure l’ajout de données simulées variées provenant d’environnements générés par ordinateur, la gestion de robots avec un nombre variable de bras ou de doigts, l’utilisation de combinaisons diverses de capteurs (caméras de profondeur, capteurs tactiles, etc.), et même la combinaison de tâches de manipulation et de locomotion.
RT-X a ouvert la voie à de tels travaux prometteurs, mais les développements techniques les plus passionnants sont encore à venir. Ce n’est qu’un début. Grâce à cette première étape, on espère pouvoir créer ensemble l’avenir de la robotique : un avenir où des cerveaux robotiques polyvalents pourront piloter n’importe quel robot, en profitant des données partagées par tous les robots du monde.
En unissant leurs efforts, les laboratoires et chercheurs devraient pouvoir repousser toujours plus loin les limites des capacités générales et de la polyvalence des systèmes robotiques contrôlés par intelligence artificielle.